Strategies to defeat No Fault Found
Safe and continued operation of military platforms in all domains, from UAS to support helicopters to communications vehicles, depends on proactive and reactive maintenance activities to sustain their safety and capability. As these platforms and systems mature with time and usage the emphasis on dedicated maintenance activity to sustain the integrity of their structure and systems must increase accordingly.
For avionics systems and the Electrical Wiring and Interconnection System (EWIS), chinks in the armour of their System Integrity begin to appear with increasing regularity in the guise of random, intermittent faults: fault which are often categorised as ‘No Fault Found’ (NFF) occurrences. NFFs occur when the fault’s root cause cannot be found, and they have a multi-million pound impact on operational availability and cost.
System Integrity
System Integrity is the bedrock of Availability and Reliability. It can be defined as the ability of a system to provide its required performance without being degraded or impaired by actual usage or by exposure to its intended operating environments throughout its intended service life. Its fundamental components are listed in the picture below: the Design of the item, the Environment in which it is to function and it’s Usage, encompassing operation by the end-user and support.
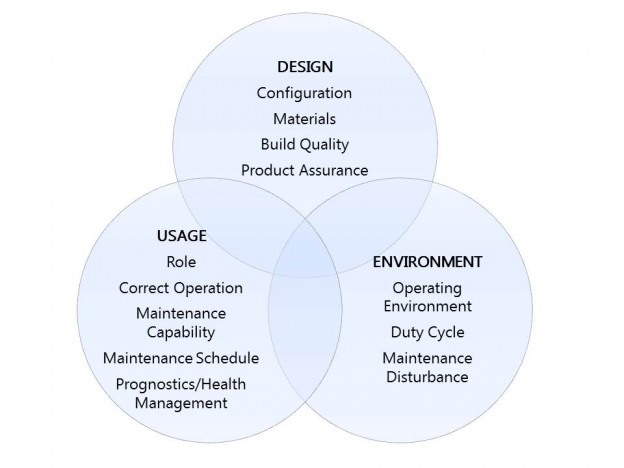
When the balance between these 3 components is exceeded System Integrity is compromised, and when this happens in avionics and EWIS the ensuing degradation manifests itself as intermittent faults, which in turn present intermittent symptoms. These are extremely difficult for technicians to detect and isolate during corrective maintenance, meaning that they frequently resort to speculative replacements of Line Replaceable Units (LRUs)…only for the original fault to return.
This cycle of activity was examined during a maintenance study of an MOD avionics mission system. The study revealed that out of over 6000 hours of corrective maintenance, repairs were successful in only 41% of the time. This 41% was not limited to “first-time-fixes” since it comprised all successful repair outcomes, including those which were successful only after multiple repair attempts. Unsuccessful repair outcomes fell into 2 main categories: repairs where the activity undertaken was a system functional test only (33%), and repairs where additional work was carried out, such as an LRU change (26%).
The latter approach leads to major waste because it perpetuates a ‘phantom supply chain’ that procures more and more of the items which are always being replaced, even though they don’t actually rectify the fault. Furthermore, thousands of hours a year are unintentionally wasted on not fixing things ‘right first time, every time’, which has obvious implications for operational availability.
So how do you break the cycle? You need a step-change in “first-time-fix” capability.
First-Time-Fix: more Availability for less Cost
There are 2 fundamental principles that underpin the step-change improvement of repair success rates:
- “Get the data”, so that decisions are made using knowledge not assumptions.
- Reliability is driven by System Integrity: fault root causes will be predominantly associated with items that are most vulnerable to their System Integrity being compromised.
The cycle of activities that can be applied to improving diagnostic and repair success is illustrated in the diagram below.
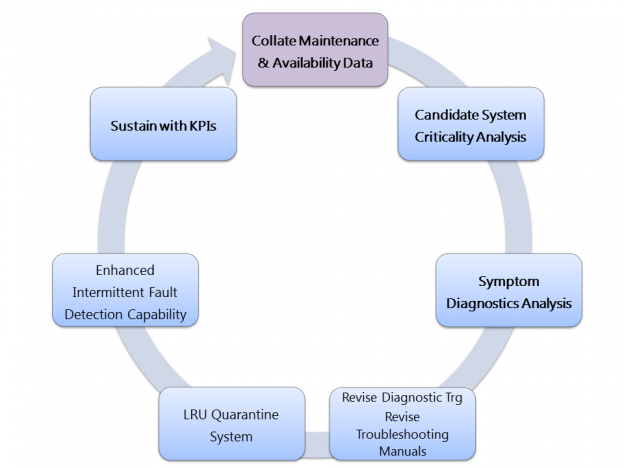
The cycle starts with obtaining the relevant supporting data and is followed by a number of steps to review and act upon that data, before sustaining the improvements by appropriate KPIs: and then running through the cycle again – either as a ‘second pass’ on the same systems/components, or by expanding the approach to other items. The running order of the items shown in bold text in the above diagram is fixed, whereas the remaining 3 items can be undertaken together in any order and/or in parallel.
The cycle runs as follows:
- The starting point is to get the relevant maintenance and availability data from multiple sources such as: operator logs, mission success data, Maintenance Information System (such as LITS or GOLDesp) and OEM repair feedback.
- Using the data, conduct a Criticality Analysis of systems by scoring their impact in terms of safety-criticality, mission-criticality, System Integrity, repair cost, repair time and so on. Scoring in this way results in a Pareto-like curve, and the candidate systems or components to focus effort on will be readily apparent.
- The maintenance data for the candidate system will contain significant amounts of symptom data in non-standardised, free text formats. Analysis of this data will soon reveal common symptoms. The next stage of the analysis is to link those Symptoms to the root cause Faults, and then to the genuinely successful Fixes. This Symptom/Fault/Fix data approach has been employed in highly successful fashion on the Tornado fleet, resulting in a 25% reduction in pilot-reported faults.
- The Symptom-Fault-Fix data is then used to revise and refine fault isolation information and guidance in training and in technical publications.
- If the data reveals a high proportion of erroneous Line Replaceable Unit (LRU) replacements, these can be contained by applying a ‘Ship or Shelf’ quarantine programme, such that the LRU is only sent for repair if its replacement is confirmed to fix the fault. FedEx saves $2M per year on its fleet using this method, and a similar approach is in use on the UK Eurofighter Typhoon fleet.
- The most vulnerable areas to System Integrity degradation are cables, connectors and LRU interconnects, resulting in the dreaded intermittent faults. Once arbitrary LRU changes have been ruled out of the diagnosis the only remaining option to solve these problems is the use of test equipment optimised for intermittent fault detection and isolation.
- The final stage is to introduce KPIs to aid the sustainment of improvements to repair success rates.
Symptom. Fault. Fix.
In an industry-wide survey conducted by Copernicus Technology Ltd, data analysis was listed as the top tool used against NFF but the respondents stated that their preferred approach would actually be to improve technician training and troubleshooting manuals. These are indeed pivotal actions in striving for “first-time-fix” but it is impossible to achieve without first exploiting the right data to provide the Symptom/Fault/Fix-driven focus and context for the subsequent repair-success improvement approach summarised in this article.
[This Copernicus Technology article was first published in the Defence Management Journal - Issue 59, Winter 2012]